BHeap algorithm
2016-10-15
I started a personal cruisade some time ago against selecting algorithms based on average time while ignoring worst case runtimes. I've posted about this here before:
Several years ago I was toying with Heaps. The normal model for a heap is that the average run-time is O(log(n)) per operation, and the worst-case is the same. While theoretically true, in practice you rarely know the size of the data you are working with before-hand, and if you are ever wrong you have to allocate more space. Since heaps are by default stored flat in an array this means *copying* the entire heap in to thhe new larger array. This operatin is in fact O(n). Thus, in practice most uses of Heaps are actually worst-case O(n).
Well... that's kind of horrible. So, I tried implementing one as a literal in-memory tree structure instead of an array. I called this a "bounded" heap (since it has a stricter bound). This gets a true worst-case O(log(n)) (assuming allocation time for new nodes is bounded). Unfortunately the performance is abysmal. We're talking 5 or 6 times worse average case, making it a pretty hard sell to convince anyone to use such an algorithm.
So, I got an idea. What if we use the ideas of a Btree in a Heap. That is, allocate chunks of memory and store pieces of the heap in them. A the time I got an outline for an algorithm I call a Bheap (creatively), but I never got around to implementing it.
I finally got it working and benchmarked it recently. Here's an outline for the Bheap algorithm. If you want full details you can just read my implementation, linked at the bottom:
Bheap algorithm:
Lets define a "Node". Each node contains an array. The first half of the array is a heap of data, exactly as normal. The second half is still layed out like a heap, but it's an indirect to other "Nodes", that is heaps. So, in principle it's just one big heap, but broken up in to chunks.
But, there's one catch. If we did this naively we would fill the first node with a bunc hof elements, then we'd allocate it's first child node and put one element there, then we'd allocate the second and put one element there. That's a total waste of memory (wasting approximately 1/arity the memory it uses). So, we modify things to fill the allocated node before it creates a new one... Heaps don't depend on much more than the heap ordering, so nothing is significantly changed.
There's only one more catch. Once we fill the last node we can allocate at a given level, we need to start filling the next level. As an optimization instead off walking down from the root we simply start making a our next child below the current tail. This is an idea I took from my first bounded heap algorithm. To make this work we fill nodes going left, then going right. There's some intracacies to making that work in practice, see the code for details.
Predicted Performance:
This algorithm has 2 neat advantages over a normal heap
1) It does exactly what I planned, allocating a small chunk of data at once, and never having to do a linear time operation... yet it's quite memory efficient. It uses ~2x the memory of a normal heap, due to the pointer indirects, and wastes at worst 1 nodes worth of space... not bad.
2) It should get better locality than a normal heap. Once downside of a normal heap is that a nodes children are located at 2i+1 and 2i+2. That means that after the first few elements all operations are non-local as far as caching goes. This algorithm keeps resetting that every time we go to a new node, so it should peform better cache-wise.
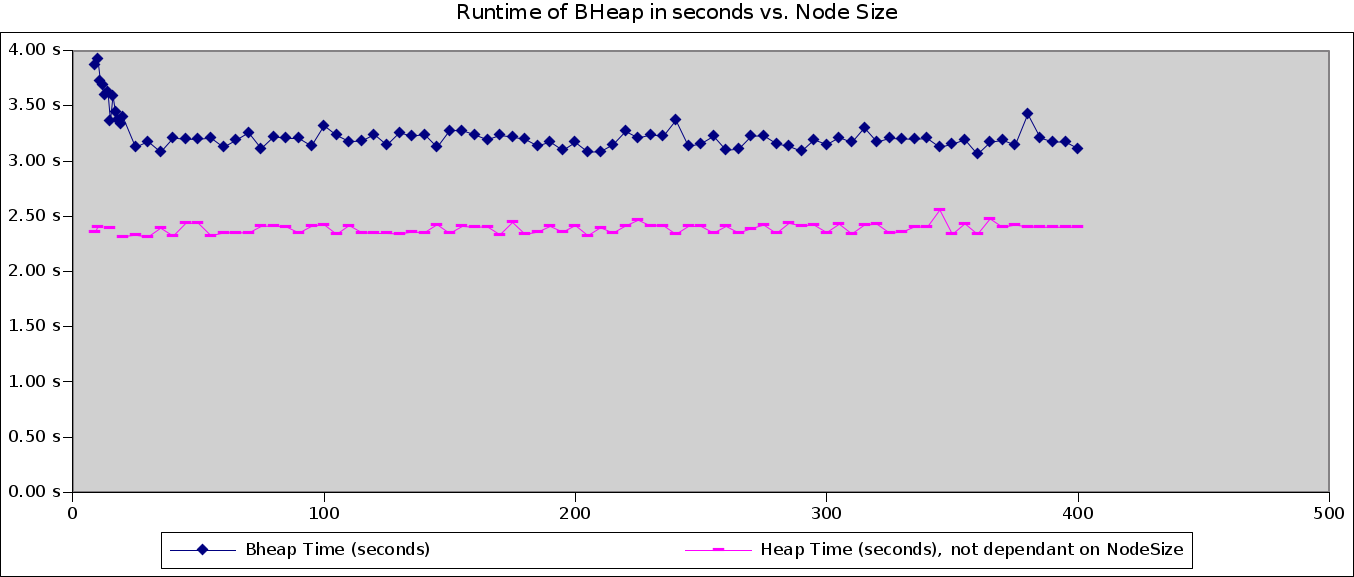
I graphed the HeapTime for a whole lot of points just to give an idea of what the variance looks like (lazy mans statistics, I know), but the above chart gives a pretty good clue of where the overriding factors are. In particular it looks like past ~20 elements or so there's no more gains for larger node sizes and constant factors related to the extra BHeap logic become dominant.
I've left out BoundedHeap data because it's just not interesting, it varies from 13 to 15 seconds, that's all there is to know.