Median Find
2018-12-19
Similar to Radix Sort, I thought it might be interesting to see how worst-case linear time medianfind actually performed. Since the algorithm is identical to expected-case linear-time medianfind (usually called quickselect), except for the pivot selection, I elected to add a boolean to the template to switch between them (since it's in the template it'll get compiled out anyway). Before we go in to the results, here's a quick refresher on these algorithms:
Problem Statement
Imagine you have a sorted array. If you want the K'th largest element, you can simply look at the element in location K in the array. Comparison-based sorting an array takes O(Nlog(N)) time (strictly speaking the theoretical limit is log-star, but it doesn't really matter). What if we want to do this without sorting the array first?
Quick Select
Quick select chooses a pivot and runs through the array throwing elements in to 2 buckets... smaller and larger thanthe pivot. Then it looks the number of elements in the buckets to tell which one contains the k'th element, and recurses. We can prove we usually choose a good pivot and this is expected O(N) time. But it's worst-case is much worse.
Worst-case-linear Quick Select
What if we always chose the right pivot? Or at least... a good *enough* pivot. This is how we build our worst-case-linear quick select algorithm. It's a really cool trick, but it's been covered in many places. So if you want to know how it works you can check wikipedia, or this nice explanation .
Real World performance
All of that is great in theory, but what is the *actual* performance of these things... well, in a benchmark, but at least on a real computer.
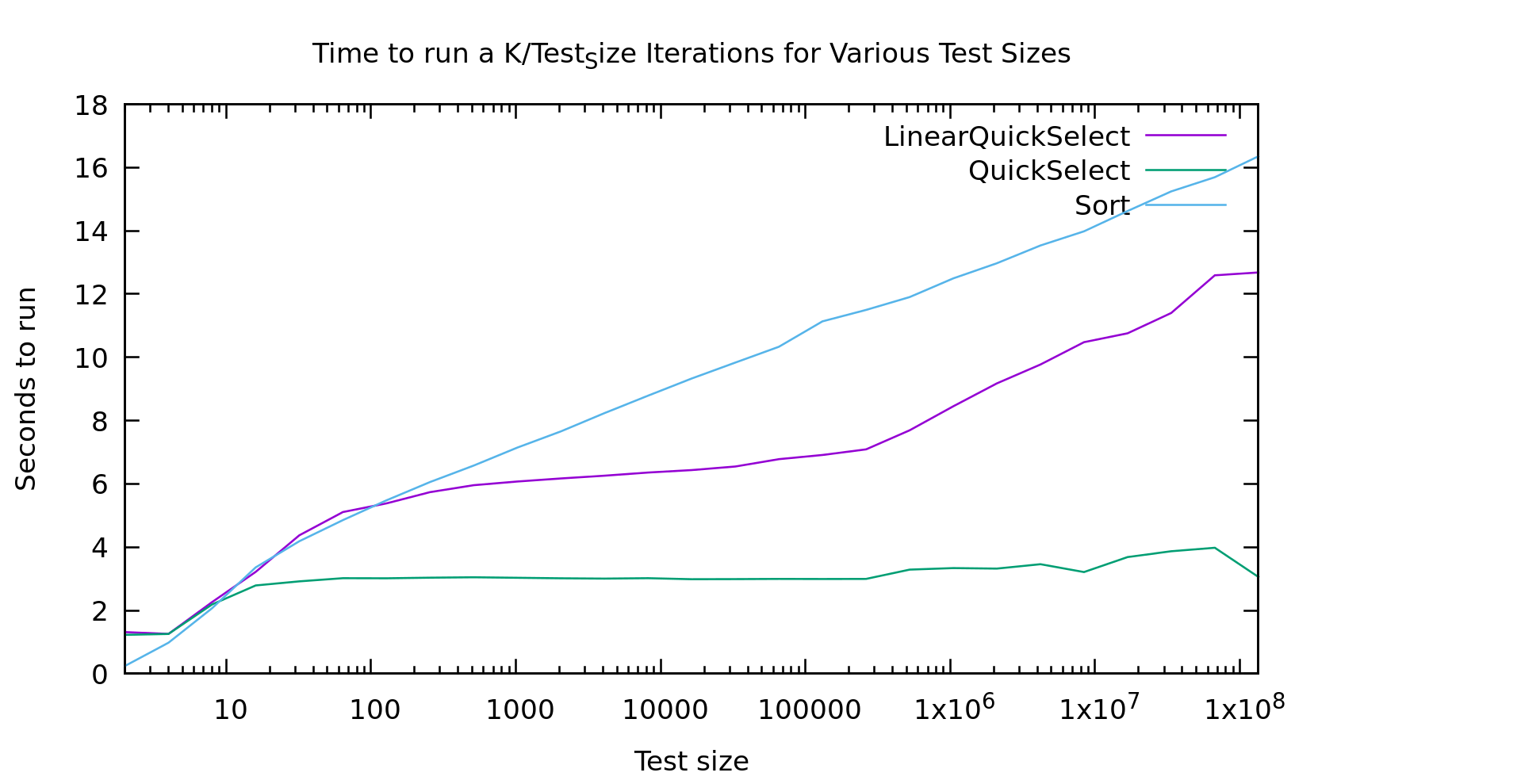
As usual I'm working on an array of test_size k/test_size times, so we work over the same number of array-cells at every point on the graph: small arrays many-times on the left, and large arrays fewer-times on the right.
For a while I was pretty upset about these results. The runtimes for "lineartime" quickselect look more like quicksort (the algorithm displayed as the "sort" line) then they do like basic quickselect. In short... that doesn't look linear at all. What the heck?
I must have a bug in my code right? This algorithm was proved linear by people much smarter than me. So, my first step was to double-check my code and make sure it was working (it wasn't, but the graph above is from after I fixed it). I double, triple, and quadrouple checked it. I wrote an extra unittest for the helper function that finds the pivot, to make sure it was returning a good pivot. Still, as you see above, the graph looked wrong.
I finally mentioned this to some friends and showed them the graph. Someone suggested I count the "operations" to see if they looked linear. I implemented my medianfind algorithm using a seperate index array. That way I could output the index of the k'th element in the *original* array. From there everything is done "in place" in that one index array. As a result, swapping two elements is my most common operation. That seemed like a pretty accurate represention of "operations". So, here's what that graph looks like.
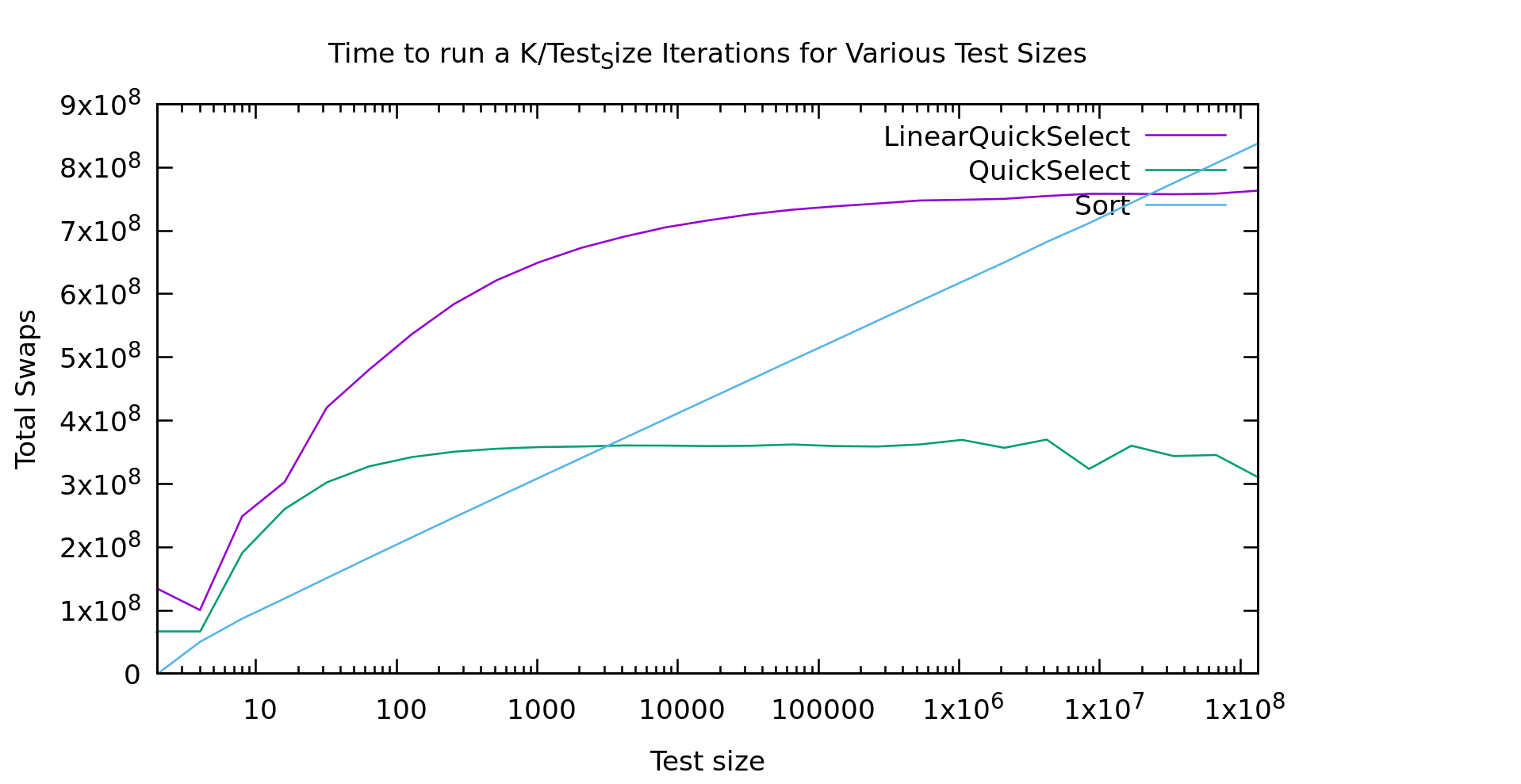
Now THAT look's a bit more linear! It's not exactly a flat line, but it looks asymptotic to a flat line, and thus classified as O(N). Cool... So, why doesn't the first graph look like this?
Real machines are weird. That index array I'm storing is HUGE. In fact, it's twice the size of the original array, because the original is uint32_t's and my index array is size_t's for correctness on really large datasets. The first bump is similar in both graphs, but then a little farther to the right in the time graph we see it go crazy... that is probably the algorithm starting to thrash the cache. Presumably if I made it big enough we'd see it go linear again. That said, if we go that large we're soon running on a NUMA machine, with even more layers of slowness, or hitting swap.
So, should you *ever* use guaranteed linear-time medianfind? Probably not. If there is a case it's vanishingly rare. It happens pivot-selection distributes well, so there's probably a use there? But, if you just used the "fastsort" we talked about in my last post you'd get even better performance, and it's still linear, AND it distributes well too! It's not comparison-based of course, but there are very few things that can't be radixed usefully with enough of them, and if you're stubborn enough about it.
Big O notation didn't end up proving all that useful to us in this case did it? Big O is usually a good indicator of what algorithm will be faster when run on large amounts of data. The problem is, what is large? Computers are finite, and sometimes "large" is so large that computers aren't that big, or their behavior changes at those sizes.