Sort Benchmarks and Modern Processors
2018-12-13
A couple of days ago I realized I'd never actually sat down and written a Radix Sort. For the Computer Scientists among us, we spent a lot of time in school learning about various comparison based sorts (quick sort, selection sort, merge sort, etc.), and how they compare to the theoretical lower bound. Radix sort is mentioned as interesting in that, since it's not comparison based, it can beat those bounds. They vaguely explain it, and move on.
In practice MOST sorting in actual code is done using quick sort, due to it's average runtime. I've ranted on this blog before about average vs. worst-case, and how I think software engineers tend to greatly over-emphasis average case... but even putting that aside, take a look at this graph.
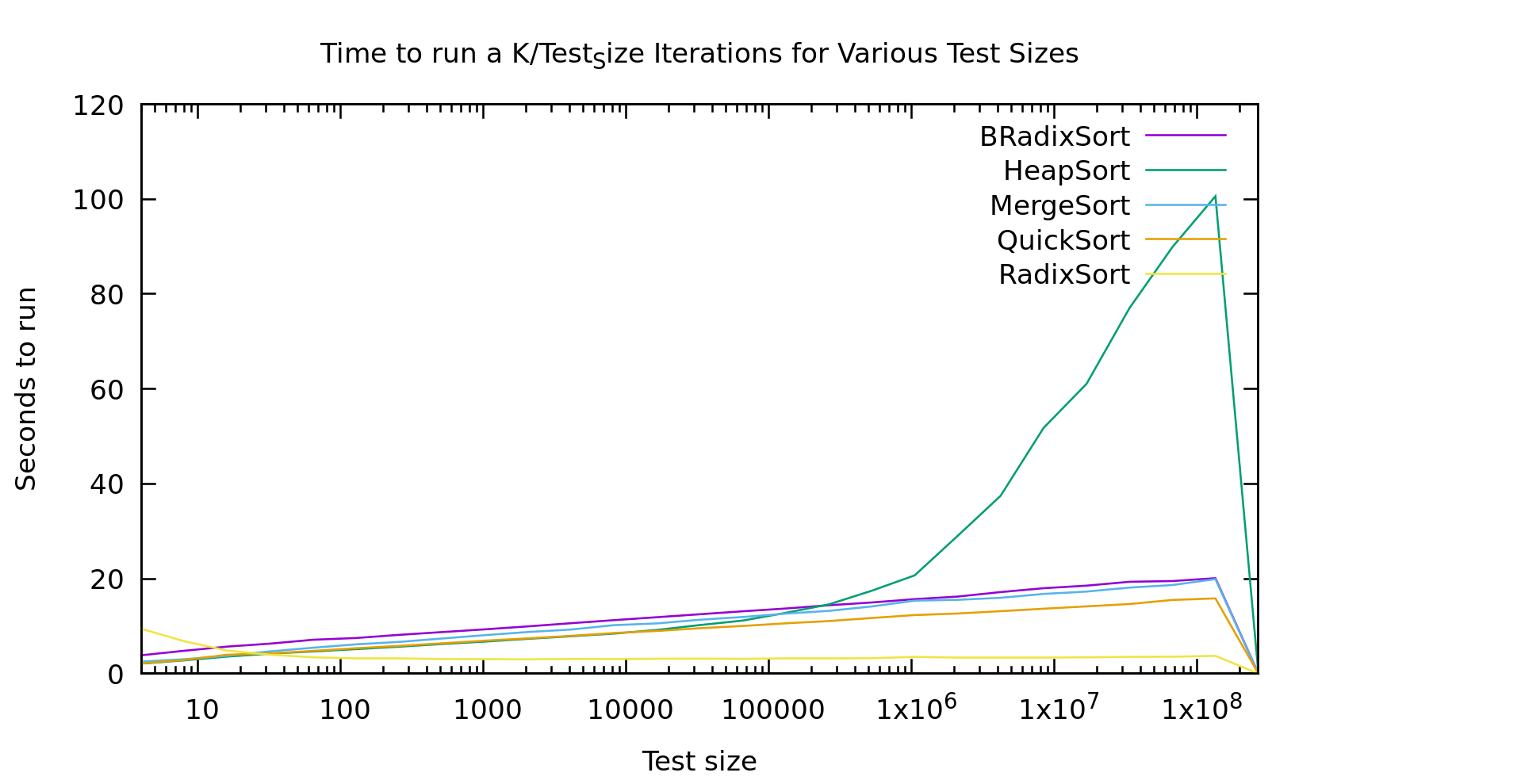
BRadixSort is a most-significant-bit first in-place binary radix sort. RadixSort is a least-significant-bit first radix sort using 32 buckets. Also, just for disclosure this is sorting unsigned 32 bit ints on my old Intel Core i7-4600U laptop.
I've shown graphs like this on this blog before, but I think I explained them poorly. Every point on this graph involves an algorithm running on the same TOTAL number of elements. The difference as you go right is that it's sorting larger and larger arrays, while doing it fewer and fewer times. This way the graph drops out the effects of just sorting more elements, and instead shows the non-linearities in varous algorithms as they work with larger and larger arrays.
Make sense?
Now. Most of these results are about what you'd expect if you've got a background in this field. Except three oddities.
- Heap Sort seems to hit a threshold list-size where it starts performing really poorly. It was looking similar to the other O(nlog(n)) algorithms, then it takes off for the skies.
- Take a look at Radix Sort below 100 elements. It gets *faster* as it runs on more elements.
- Why isn't Binary Radix Sort behaving like it's time is O(nlog(k)) like Radix Sort is?
Heap Sort
With heap Sort I'm I think this is related to cache sizes. We all know that quick sort and merge sort are preferred over heapsort due to constant factors right? Well sure, but here we see heap sort is actually faster than merge sort for smaller lists (this could actually potentially be useful, since it's also in-place and stable). I think the problem is that as heaps get bigger you completely lose adjascency between a node and it's children. This means basically every access is random, no prefetching and caching advantages. My machine has a 4MB cache. It falls apart just about the time it starts cache-thrashing, while other algorithms are taking advantage of prefetch logic by running liner through the data
Radix Sort
Radix Sort should take O(n*log(k)) where k is the largest element we're sorting. You can also think of log(k) as the number of bits in the elements we're sorting. This is of course completely linear in N, and the graph shows almost exactly that. Except that weird slope at the start.
That bump at the start has a couple possible causes. It could be branch prediction failing us horribly, or it could be walking that 32-bucket list twice. It might be interesting to try and pick it apart.
To explain why branchprediction makes sense. When we sort a tiny list over and over and over again, our algorithm isn't doing anything terribly predictable. So, very likely branch prediction *correctly* guesses that we'll loop basically every time, and never break the loop. If we then break that loop after only looking at 4 elements, we get a complete pipeline dump every 4 elements... ouch. Radix Sort scans both the data, and it's index array twice per pass. It does this for log(k)/buckets passes. But, each pass goes straight through list. This means LOTS of loops to mispredict, while on big lists prefetching logic knows *exactly* what we're doing, so it's able to pull in the data before we need it. Given no other factors slowing it down it actually gets faster on larger arrays, where prediction is basically perfect.
Binary Radix Sort
Binary radix is supposed to have the same time complexity as Radix Sort, but that graph doesn't look "linear in N' at all. If it was linear in N it would be a flat line like Radix Sort is. Here's my guess as to what's going on. It's true that Binary Radix Sort will take at MOST log_2(K) passes. But, that's a lot of passes. In fact, in practice log(K) is usually larger than log(N). After all, we usually work with numbers the same size or larger than the size of our address space right? Even if we limit K to 32 bits, it's still larger than most lists we'd sort on a single machine.
Binary Radix Sort is also capable of terminating early. Since it's recursive, at some point a sublist only has size 1 and there's no need to keep iterating through the bits at that point. This means the average runtime is actually more like N*min(log(N),log(K)). For every list in the graph shown here Log(N) < Log(K) so it's effectively an Nlog(N) algorithm. My guess is that if I did another 4 or so points we'd see that line go flat, but I'm just not sorting big enough arrays ('cause I don't want to wait that long).
Conclusion
There are several takeaways here:
- People should really be using RadixSort more (but based on my results, probably not for short lists, call out to selection or quicksort if it's short, smaller radicies might do better). Comparison based sorts are useful when your sorting needs to be super-generic, but in reality we are almost always sorting numbers or strings.
- HeapSort is underappreciated for small data sets. It doesn't diverge from quicksort until around 10k elements; Yet, unlike quicksort, heapsort is guaranteed O(nlog(n)). Plus it's stable as a bonus, and in place unlike mergesort.
- BinaryRadix has a place as well. While my version isn't stable, it is in place, and it's theoretical worst-case is O(Nlog(N)). The only other commonly used algorithm with those 2 properties is heapsort. While it's a bit slower than heapsort on small lists, it destroys it as heapsort runs afoul of the bad cache behavior. As we discussed it should even go flat at some point (or earlier if you have smaller keys).
One last note. I don't want to oversell my results. Please keep in mind that these are MY implementations. I may well be missing a tweak that would get a significant speedup somewhere. I spent a little time on RadixSort to get this performance. At first my constant factors were so bad it wouldn't have beaten anything until ~100k elements or so. Declaring constants as constants, replacing division ops with bit ops, etc. sped it up by around 5X. Micro-optomization is usually a waste of time, but here is where it can really pay off.
As always you can find this code on github https://github.com/multilinear/datastructures_C--11.git/ .