Benchmark of all major dictionary structures
2017-04-20
I've been writing basically every major datastructure, one at a time.
I wrote up heaps a little while ago:
http://www.blog.computersarehard.net/2017/02/a-better-heap.html
I've now finished writing and benchmarking all the common dictionary datastructures.
Note that at every point in this graph the same amount of work is being done. At each point we put "test_size" random elements in to the datastructure, and then remove them. We do this 134217728/test_size times, and time the *total*. Thus we're always putting in and taking out 134217728 elements.
As a result, this graph is showing is how the size of a datastructure impacts it's performance. Note that the graph is logarithmic on the X axis, so it's not completely dominated by the larger tests.
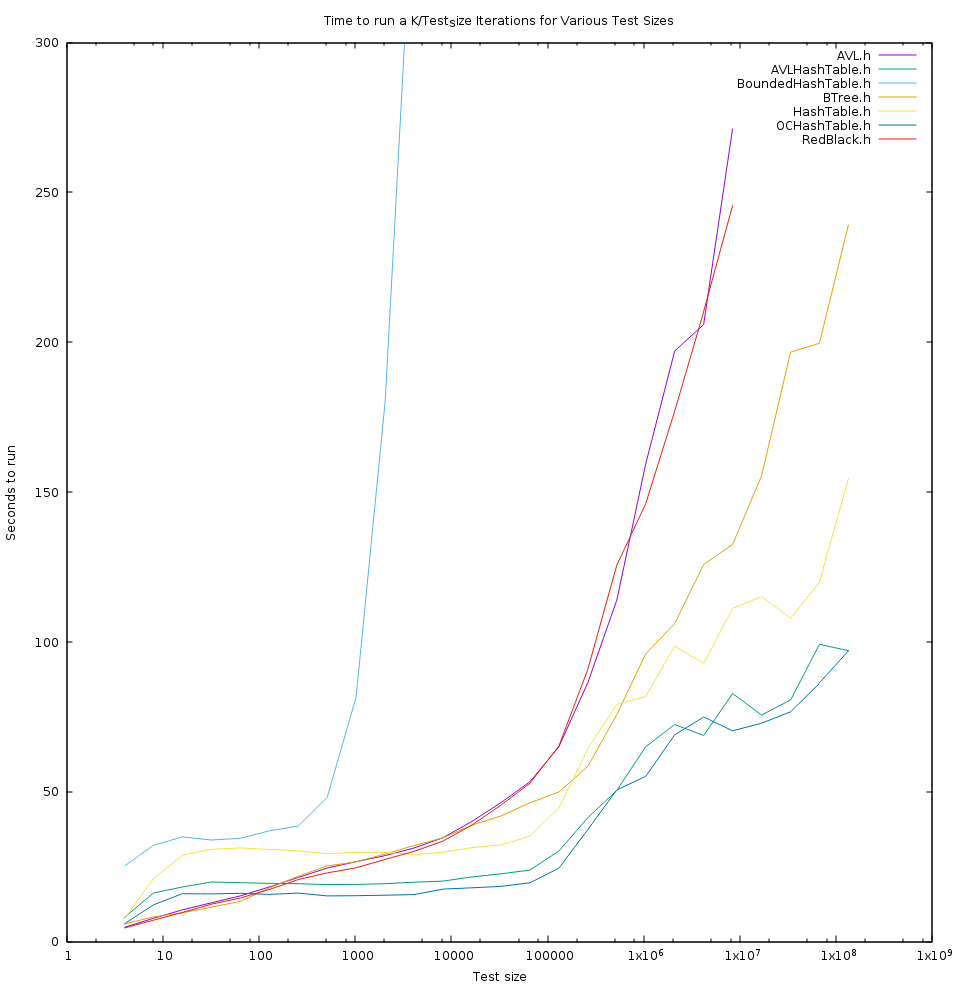
First, lets talk about what each of these algorithms *is*. As a note all of these algorithms resize automatically, both up and down.
- AVL: This is a relatively standard AVL tree with external allocation. I was unable to find an implementation that was correct and balanced, so I rederived some details myself.
- O(log(n) all operations
- RedBlack: This is a highly optimized red-black tree implementation (much more time was spent on it than AVL, due to AVL outperforming it in my testing perviously, I assumed I must have made a mistake).
- O(log(n)) all operations
- BTree: This is just a standard btree implementation, tuned with a fairly efficient arity
- O(log(n)) all operations
- Hashtable: This is a standard open chaining hashtable, using dynamically sized (doubling) arrays for the chaining
- O(N) worst case, O(log(N)) amortized
- OCHashTable: This is a standard open chaining hashtable, using an externally allocated linked-list for the chaining
- O(N) worst case, O(log(N)) amortized
- AVLHashTable: This is a standard open chaining hashtable, using an externally allocated AVL tree for open chaining
- O(N) worst case, O(log(N)) amortized
- BoundedHashTable: This is a giant pile of tricks. It uses an array like datastructure that can be zeroed in constant time. An AVL tree for open chaining. Rehashing on resize is distributed across operations so it rehashes a couple of elements for every op, using a link-list to find each element.
- O(Log(N)) all operations
Algorithms left out
- BtreeHashTable: This performed so poorly I pulled it out of the testing. The reason is obvious, while btree is very fast, it's not good for small datasets, and the chains in a hashtable are always small
Surprising results:
You may notice that NONE of these algorithms are even *close* to linear in practice. If every operation is amortized to constant time, as in our hashtable algorithms, the line should be completely *flat*. No more work should be done, just because the datastructure contains more data. This is even more true for the bounded-hashtable, where no operation is *ever* linear, the only reason it's log and not constant even on a per-operation basis is the AVL tree used for chaining.
I spent a while trying to find non-linearities in my testing methodology but came up with nothing. Remember, the X-axis is logarithmic Isn't that odd? If that's throwing you off, here's what it looks like graphed linearly (My data is logarithmic in nature, so the graph is pretty ugly). Whatever that is... it's not linear.
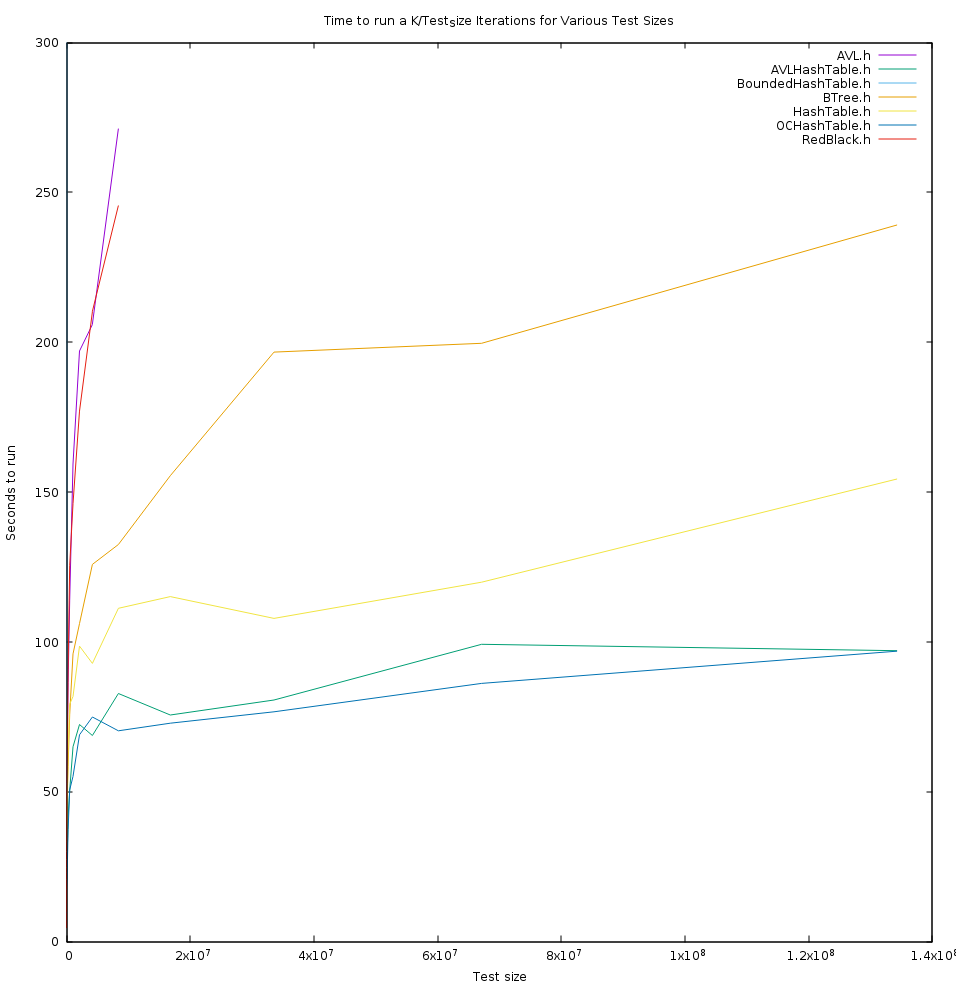
So, what's going on? My best guess is this is the computer's fault. Caching layers, memory management, etc. memmap() probably takes longer and longer to get us memory for malloc for example. I've yet to get detailed enough information to confirm this theory though.
Conclusion
Well... aside from the nonlinearity described above. OCHashtable is the clear overall winner for average runtime at any scale, no big surprise there. BTree is the clear winner for bounded algorithms of large size. AVL and RedBlack are about equivelent for small size... but given in my previous testing AVL came out a little faster, lookups should theoretically be a little faster, the implementation tested here is less optimized than red-black, and an order of magnitude simpler to code, AVL clearly beats RedBlack (as is now known generally).
This is pretty much what we would expect. I had high-hopes for BoundedHashTable, as *theoretically* it is very fast... but the constant factors seem to blow it out of the water, and it still shows up as very much non-linear. This algorithm is unable to resize arrays (as realloc zeros, which is linear), this means constantly allocating new differently sized arrays. I suspect this along with the constant factors due to algorithmic complexity is probably the cause of poor performance.
As always, full source is available here: https://github.com/multilinear/datastructures_C--11